Automated aeronautical charts private repo
First of all I’m going to show you what an aeronautical chart looks like:
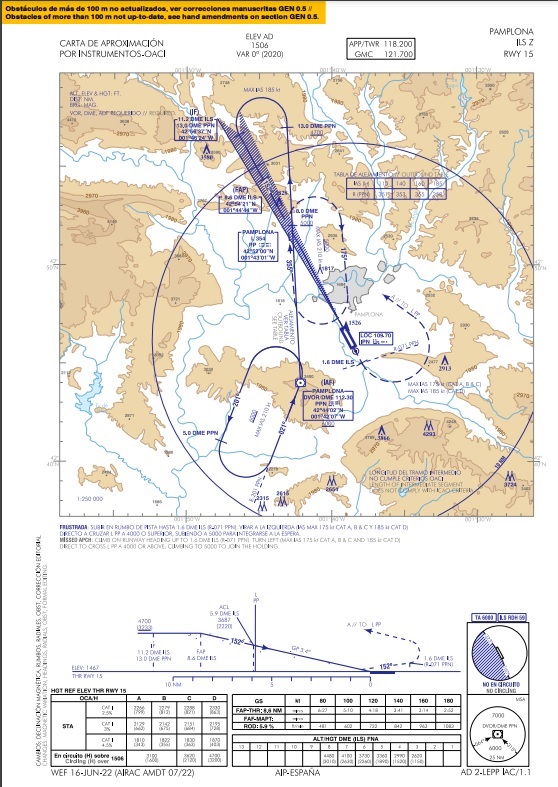
I have approximately 60 airports to keep track of and each airport has between 10 and 15 different charts. Moreover, charts get modified very often almost on a monthly basis.
airports = ['LECH', 'LERI', 'LEPP', 'LEMH', 'LELL', 'LEIB',
'LEPA_LESJ', 'LELC', 'LEGE', 'LEAL', 'LESB', 'LEPO',
'LERS', 'LXGB', 'LEAM', 'LEZG', 'LEMD', 'LEBB', 'LEXJ', 'LEBA',
'LEVX', 'LEZL', 'LEBG', 'LESA', 'LETO', 'LELN', 'LEAS', 'LEVD',
'LEGT', 'LERJ', 'LESO', 'LEVT', 'LECO', 'LEST', 'LEMO', 'LEGA',
'LEDA', 'LESU', 'LEJR', 'LEMI', 'LETL', 'GCLP', 'GCLA', 'GCXO',
'GCRR', 'GSVO', 'GSAI', 'GCTS', 'GCFV', 'GCHI', 'GEML', 'LEMG',
'LEGR', 'LEHC', 'LEBZ', 'LEBL', 'LEAB', 'LECU_LEVS', 'GCGM', 'LEVC',
'LERT', 'LERL', 'LEAG', 'LEAO', 'GEHM', 'GECE', 'LECV', 'LEEC',
'LETA', 'LELO', 'GCXM', 'LEBT']
Imagine that you have to fly to 3 distinct airports, you have to download one by one all the aeronautical charts. Two months later you have to fly the same route, but you don’t know if charts have changed, therefore you download them all again.
I have always found this task repetitive and time-consuming and I decided to make a script to automatize the process.
Requirements
I had two critical requirements to the script:
- Multithreading
- Progress bar
- Final report
Downloading the files one by one in a linear process would take forever. In order to speed up the script it had to be multithreaded. Furthermore, it had to show a progress bar for each download and a report at the end of the script.
Libraries
Script
The script has three main parts: the first one is creating the tree folder structure to store all the pdf files, the second part is to create a list with all the aeronautical charts URLs and the last one is to download them all.
Creating tree-structure directory
Main folder will be named with the today.datetime and the date of the AIRAC cycle for example: 23_12_2022(01-DEC-22). It will have as many child folders as airports to download.
def create_airport_folders(airports, access_rights, soup):
"""
Creates the folder structure where the flying charts will be saved
:param airports: list with the OACI airport codes
:param access_rights: access rights code
:param soup: bs4 request from aip.enaire.es
:return: 2 level folder structure
"""
path = create_path(soup)
try:
os.mkdir(path, access_rights)
except OSError:
print("\nCreation of the directory %s failed" % path)
else:
print("\nSuccessfully created the directory %s" % path)
for airport in airports:
try:
os.mkdir(path + "/" + airport, access_rights)
except OSError:
print("\nCreation of the directory %s failed" % (path + "/" + airport))
else:
print("\nSuccessfully created the directory %s" % (path + "/" + airport))
Creating pdf url list
Second part of the script creates a list with all the pdf URLs to download using two functions.
Parse_pdf scraps all the AD2 and AD3 pdf aeronautical charts from the main_url and returns a list.
def parse_pdf(soup):
"""
Extract AD2 and AD3 PDF names from html request
:param soup: bs4 request from aip.enaire.es
:return: List of pdf names
"""
pdf = []
for a in soup.find_all('a', href=True):
pdf.append(a['href'])
pdf_ad2 = list(filter(lambda i: ("AD2") in i,
filter(lambda i: "pdf" in i, pdf)))
pdf_ad3 = list(filter(lambda i: ("AD3") in i,
filter(lambda i: "pdf" in i, pdf)))
pdf = pdf_ad2 + pdf_ad3
return pdf
Create_url creates the long URL to download the file
def create_url(url, pdf):
"""
Joins base urls and pdf name to create the pdf base_url
:param url: URL
:param pdf: file_name
:return: URL + PDF
"""
url = ''.join([url, pdf])
return url
# Create list of urls to request
urls = list(map(aip.create_url,
itertools.repeat(url, len(aip.parse_pdf(soup))),
aip.parse_pdf(soup)))
Multithreading download
This is where the magic starts. Once we have the folder structure and the url list the scrip starts downloading all the pdf files with multithreading, and it shows a progress bar for each file.
Basically it executes this function each time a thread is available:
def download_file(url, path, file_name):
"""
Download PDF air chart from URL and saves it in the OACI airport folder
:param url: pdf URL
:param path: Parent folder path
:param file_name: pdf name
:return: pdf file
"""
try:
# Request
html = requests.get(url, stream=True) # Stream to get data in chunks for tqdm
if html.status_code != 200:
print('\nFailure Message {}'.format(html.text))
# OACI code folder
folder = re.findall(r'.*\/(.*)\/.*', url)[0]
# Save pdf to oaci airport folder
with open(path + "/" + folder + "/" + file_name, 'wb+') as f:
# Progress bar init
pbar = tqdm(unit="B",
unit_scale=True,
unit_divisor=1024,
colour="red",
total=int(html.headers['Content-Length']))
pbar.clear()
# Pbar description
pbar.set_description("Downloading {}".format(file_name))
for chunk in html.iter_content(chunk_size=1024):
if chunk:
pbar.update(len(chunk))
f.write(chunk)
pbar.close()
except requests.exceptions.RequestException as e:
print(e)
Now its play time:
threads = []
# Counters
downloads = 0
exceptions = 0
# Time counter init
t1 = time.perf_counter()
with ThreadPoolExecutor(max_workers=20) as executor:
for url in urls:
file = aip.file_name(url)
threads.append(executor.submit(aip.download_file,
url,
aip.create_path(soup),
file))
# Counter of task completed and exceptions
for task in as_completed(threads):
if task.done():
downloads += 1
if task.exception():
exceptions += 1
# Time counter end
t2 = time.perf_counter()
At the end of the script it prints a report:
# Print results
print('\n{} flying charts downloaded in {} seconds with {} exceptions.'.format(downloads,
round((t2-t1),0),
exceptions))
Usage
Execute main.py and Voilà:
python main.py
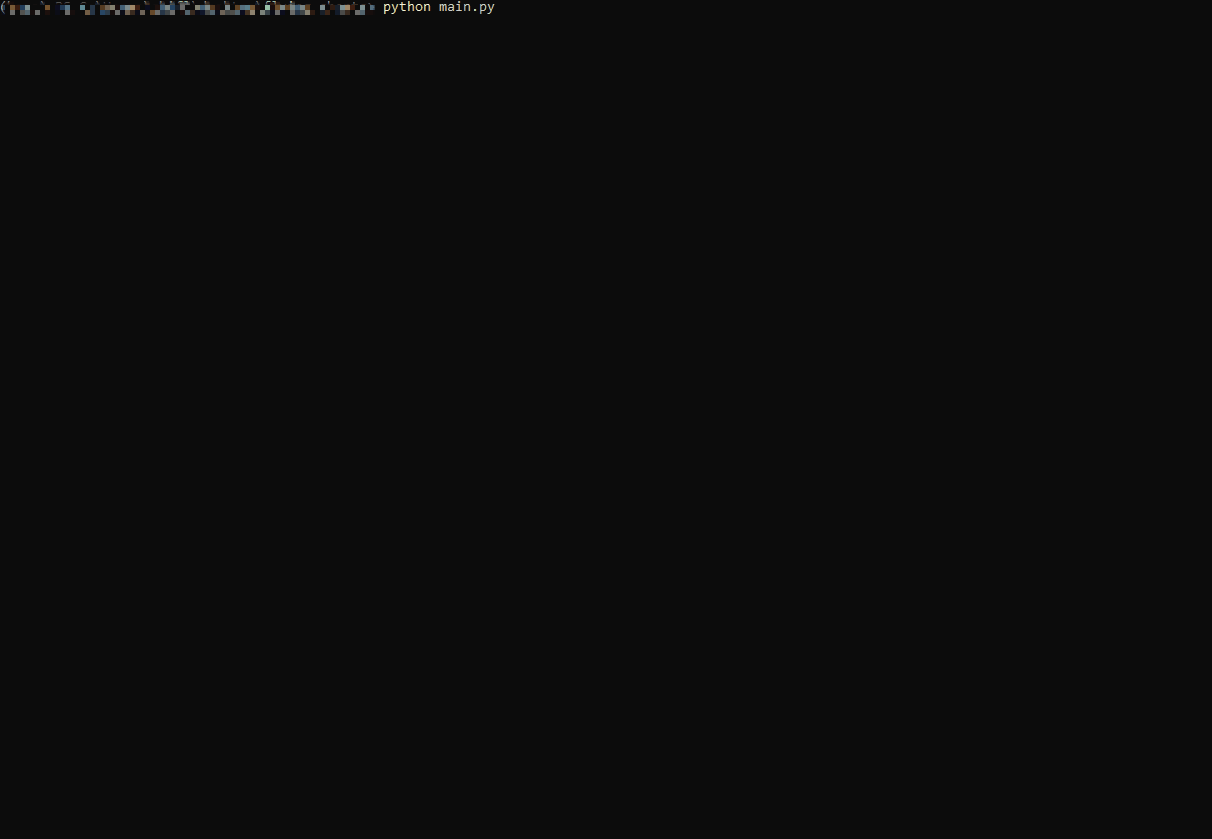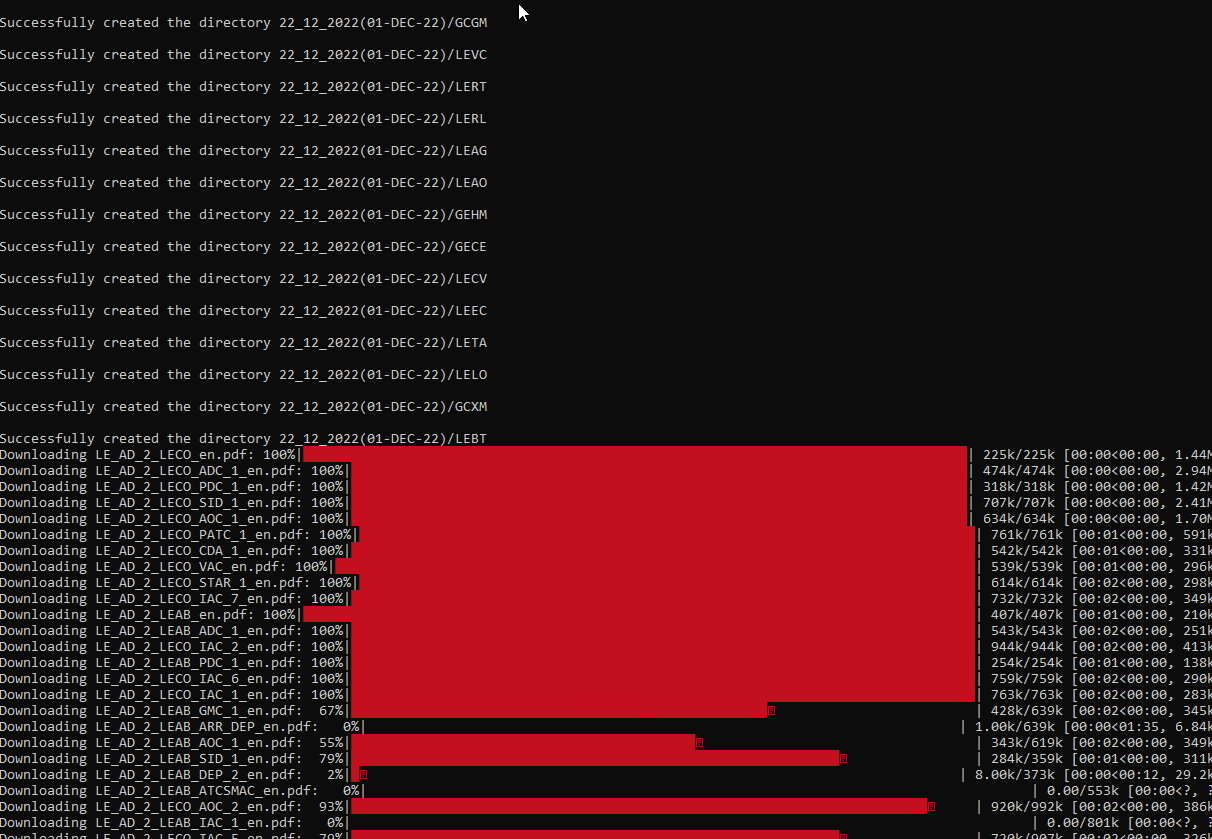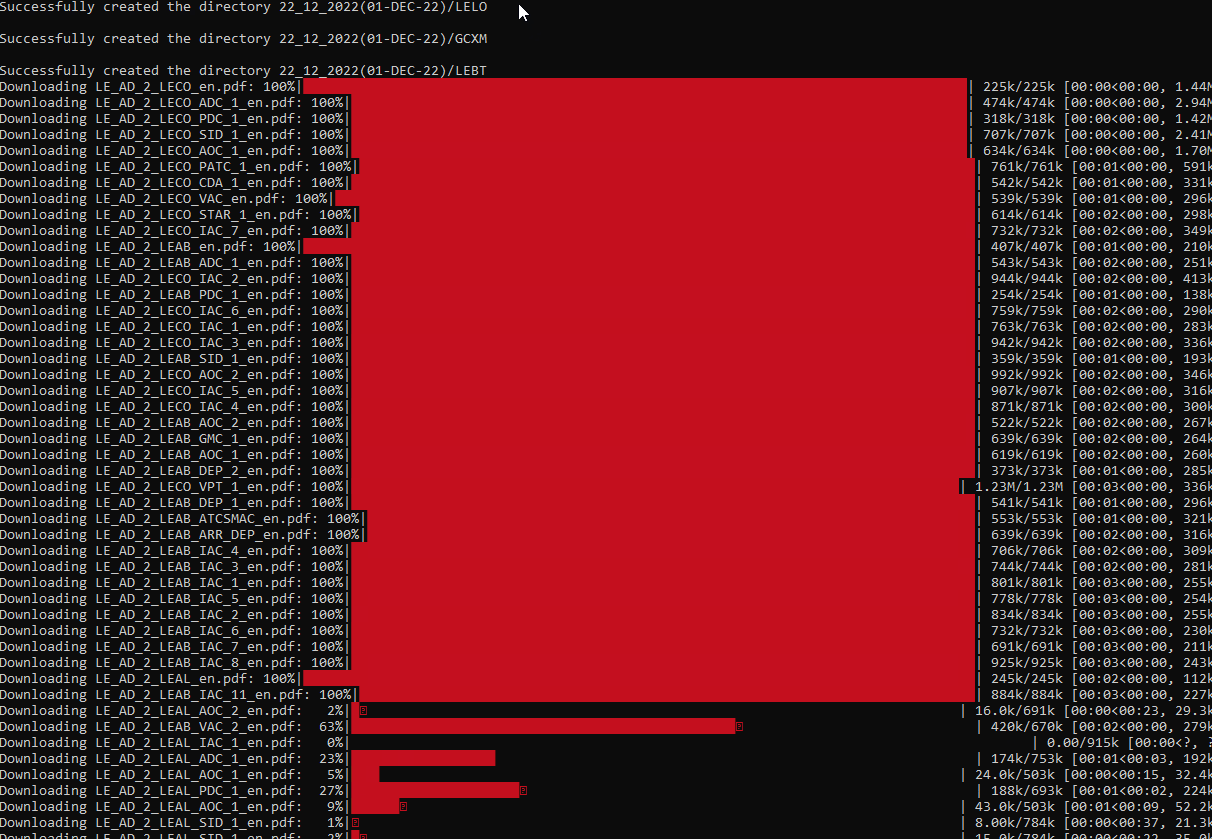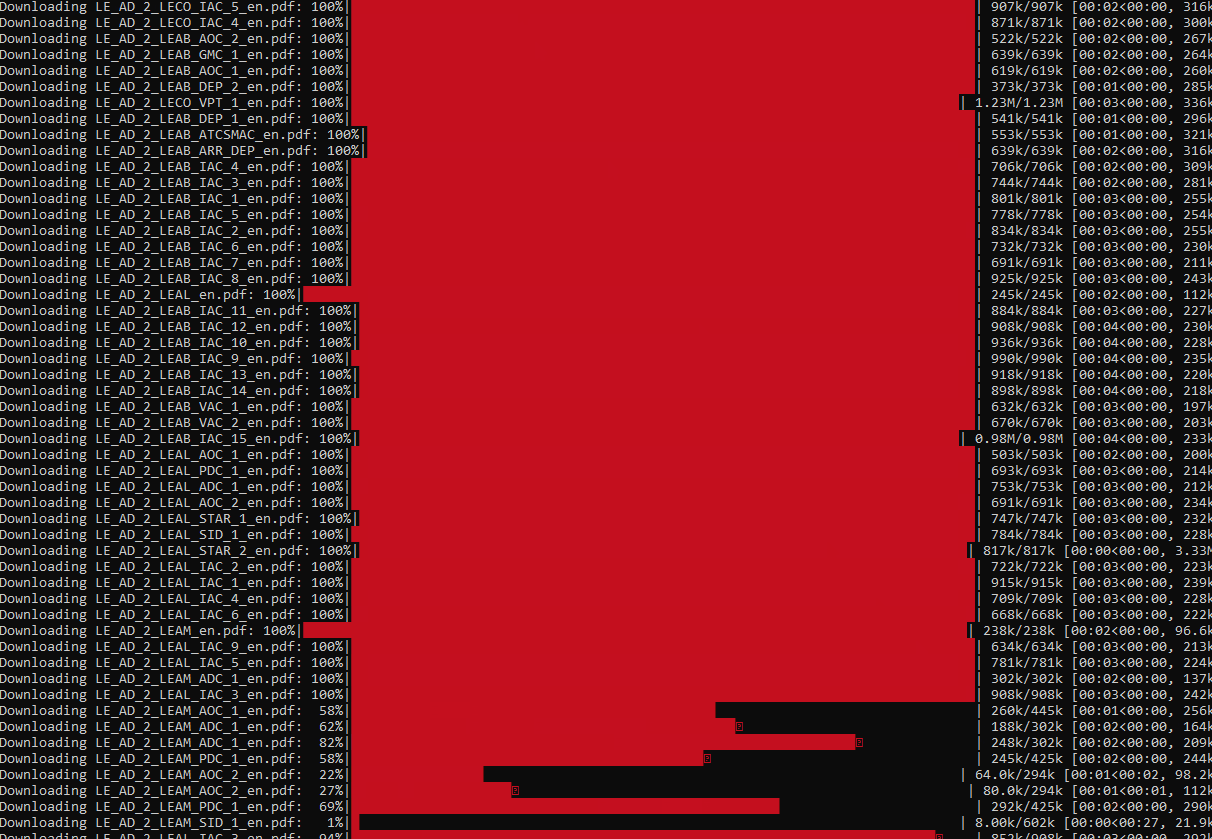
1199 flying charts downloaded in 447.0 seconds with 0 exceptions.
Fly safe!
About me
My name is Martin, and I am a Data Scientist.
Repository link on Github.

 Except where otherwise noted, this blog's content is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Except where otherwise noted, this blog's content is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.