Wikileaks Iraq War Logs Dataset
On October 2010 Wikileaks released 391.832 html Significative Action (SIGACT) files. Each file details an event occurred between January 2004 and December 2009.
Every SIGACT file contains information about the event such as number of KIA (killed in action), WIA (wounded in action), coordinates, date and time, category, type, etc.
The main idea of this project is to parse each html file and extract the tabular information embedded inside three tables and relevant information placed at the end of the html file.
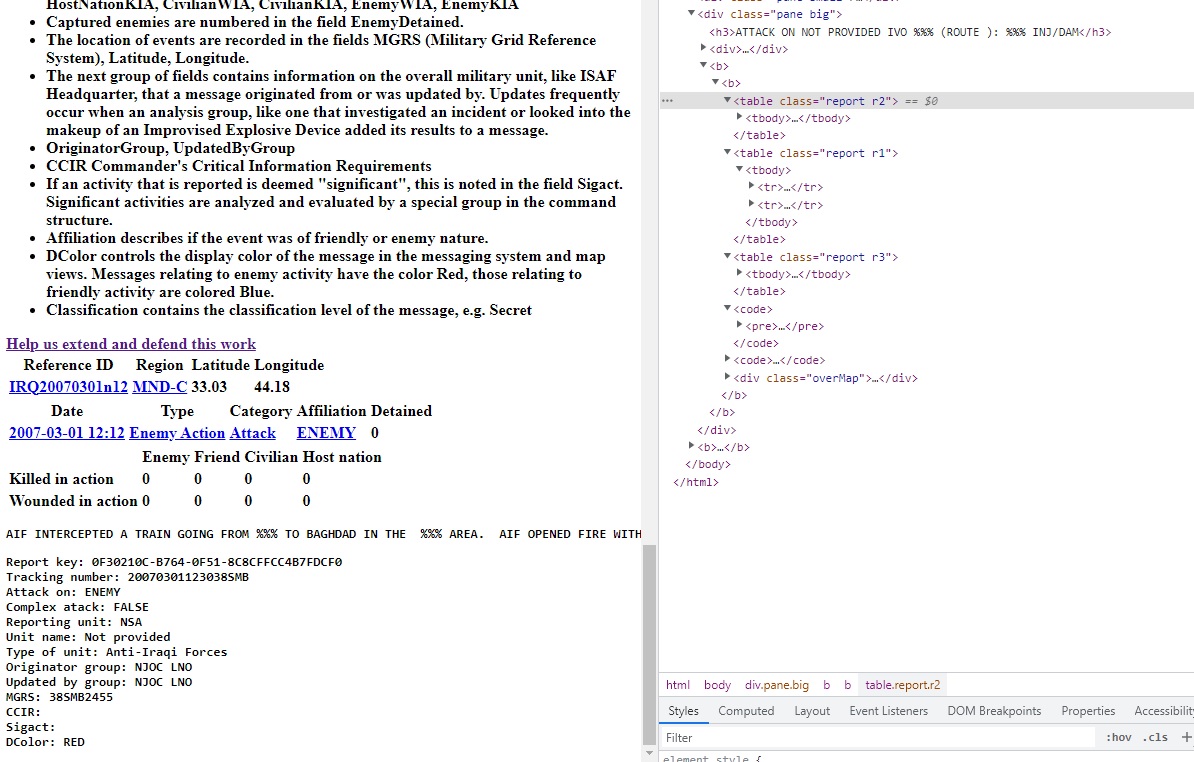
The event folder contains 391.832 files to parse and write into a csv file. Processing one after one would take a huge amount of time, but here is when multiprocessing comes in handy.
Specs
- Async multiprocessing
- Progress bar
Script
The script basically runs a worker function parsing each html file and saves the dataset row inside a queue. Another function is continuously looking at the queue and writing each row inside the csv file.
CSV headers
After all the multiprocess magic begins we have to write the dataset column headers:
def first_row(csv_file):
"""
Writes first row with column headers.
:param csv_file: path to .csv file to insert headers
:return: .csv file with headers row
"""
with open(csv_file, 'w', newline='') as f:
write = csv.writer(f)
write.writerow(['Region', 'Datetime', 'Type', 'Category', 'Affiliation',
'Detained', 'Enemy_KIA', 'Friend_KIA', 'Civilian_KIA', 'Host_nation_KIA',
'Enemy_WIA', 'Friend_WIA', 'Civilian_WIA', 'Host_nation_WIA', 'Complex_attack',
'Type_of_unit', 'MGRS'])
HTML files list
Multiprocess will save us a lot of time but, firstly we need to prepare a list with all the elements that the worker function will use as argument. Iterating top-down from the root folder structure we take all the files and put them into a HUGE list with 390000+ elements.
def flat_sigact_files(root_folder):
"""
Searches for html files in a folder tree and saves them into a list.
:param root_folder: Parent folder of sigacts html files.
:return: List with all the sigacts html file_names.
"""
files_sigact = []
for root, dirs, files in os.walk(root_folder):
for name in files:
files_sigact.append('\\'.join([root, name]))
return files_sigact
Worker function
Our information if interest in each html file is placed inside 3 tables and a block of text.
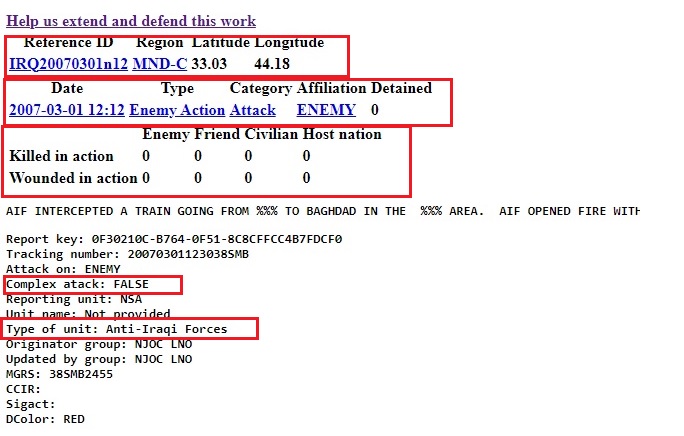
Our worker scrapes the html file and returns a list with all the important information.
def html_parser(html_file, q):
"""
Opens a html file and searches for items inside tables.
:param html_file: sigact html file.
:param q: queue object to save jobs pending to write
:return: queue item
"""
with open(html_file) as f:
soup = bs4.BeautifulSoup(f, 'html.parser')
tables = soup.find_all('table')
fields = []
index = [1, 4, 5, 6, 7, 8, 10, 11, 12, 13,
15, 16, 17, 18, 22, 25, 28]
row_sigact = []
codes = soup.find_all('code')
for i in range(0, 3):
for row in tables[i].find_all('tr'):
for column in row.find_all('td'):
fields.append(column.get_text())
for v in codes[1].strings:
fields.append(v.split(':')[-1])
for i in index:
row_sigact.append(fields[i])
q.put(row_sigact)
Listener
Once we start the worker, it won’t stop until all the html files are parsed. But we want to save each row into a csv file at the same time. To cheat the system and get away with this idea we are using a queue.
Every time a worker creates a row is placed inside an async queue. Our listener is looking at the queue at the same time rows are being created and writing them down inside the .csv file.
def listener(queue, csv_file):
"""
Searches for rows pending to write inside a queue and writes them into a .csv file.
If last job is last_row kills the listener.
:param queue: queue with jobs pending to write.
:param csv_file: path to .csv file to write rows
:return: csv file
"""
with open(csv_file, 'a', newline='') as f:
write = csv.writer(f)
while 1:
row = queue.get()
if row == 'last_row':
break
write.writerow(row)
Multiprocessing
Once we have all our functions created, we must glue up everything into a script and light it up.
# Manager to manage async queue
manager = mp.Manager()
# Queue to save jobs
q = manager.Queue()
# Number of workers
pool = mp.Pool(mp.cpu_count())
# Starting a watcher who scans the queue and writes rows to the csv file
watcher = pool.apply_async(func.listener, (q, csv_file,))
jobs = []
# Progress bar where an entire file is a chunk
with tqdm.tqdm(total=len(files_sigact)) as pbar:
for file_name in files_sigact:
# Async worker in every html file
job = pool.apply_async(func.html_parser, (file_name, q))
# Saves job object inside job list
jobs.append(job)
for job in jobs:
# Retrieve data from job object
job.get()
# Updates progress bar
pbar.update(1)
# collect results from the workers through the pool result queue
# In order to kill the watcher we put last_row as last job object
q.put('last_row')
# Stops multiprocessing tasks after all jobs are done
pool.close()
pool.join()
# Stops progress bar
pbar.close()
Usage
Execute main.py and Voilà:
python main.py


We parsed 391832 files in 31 minutes with 200 iterations per second and the .csv file looks like this:
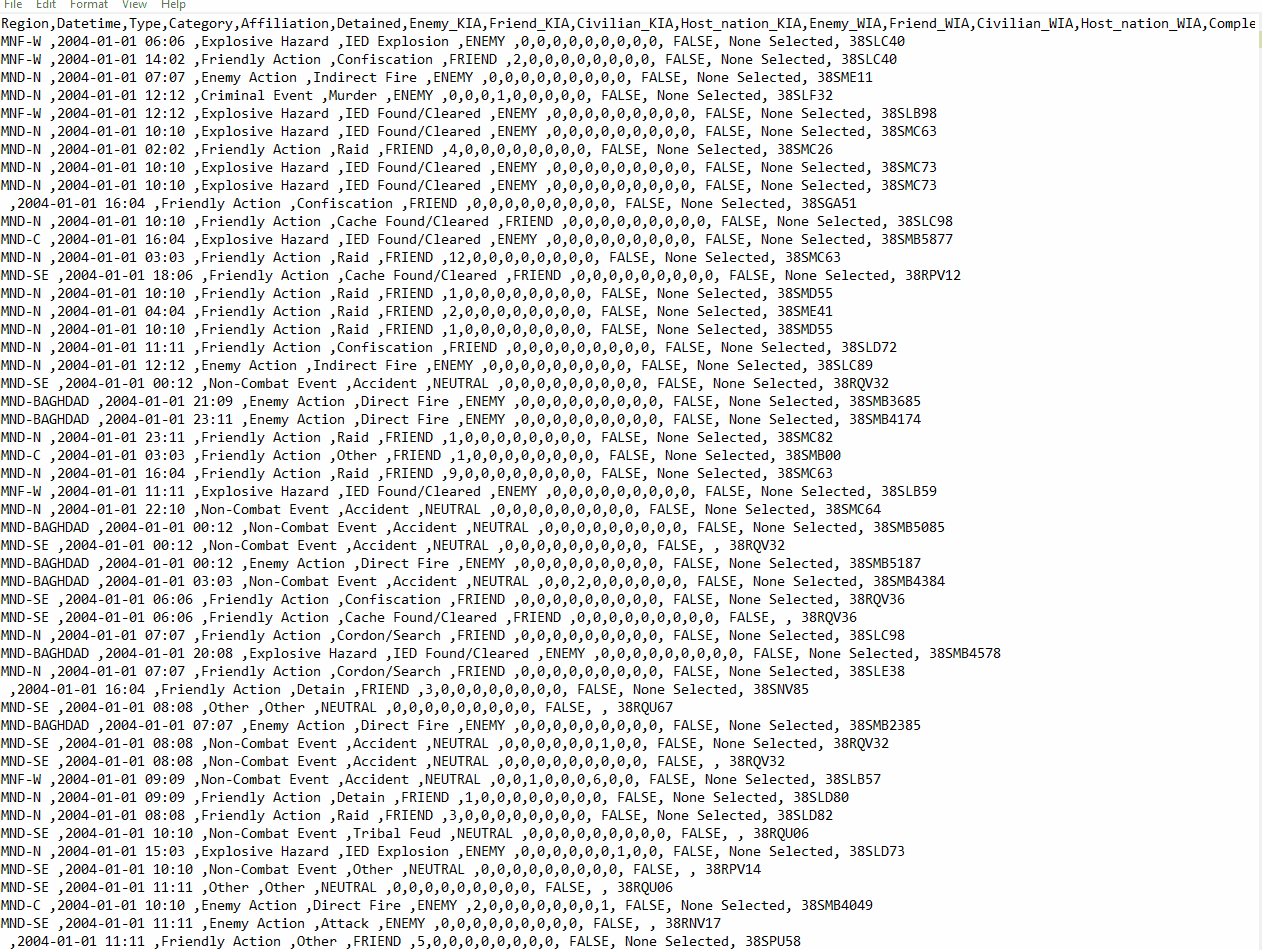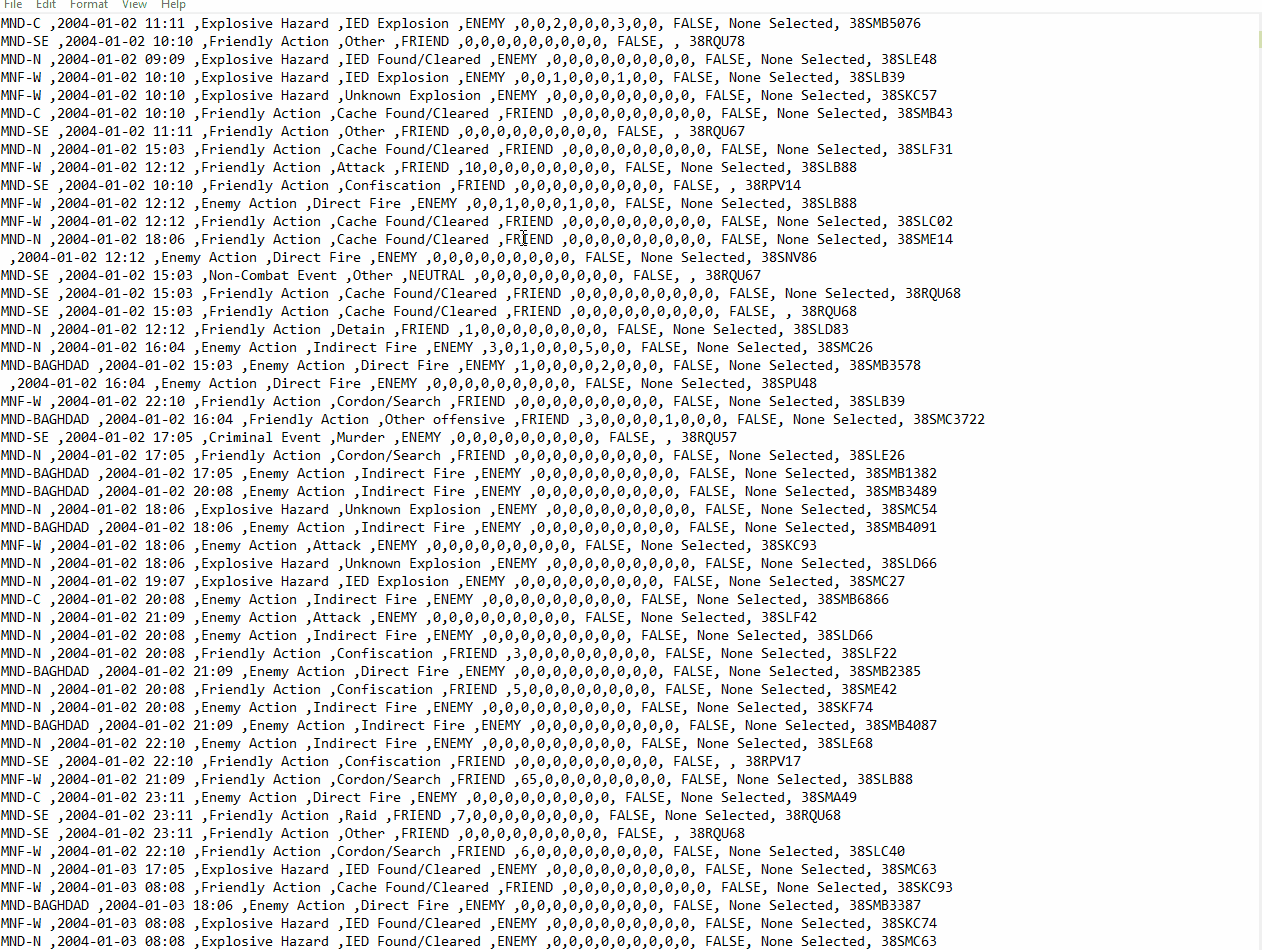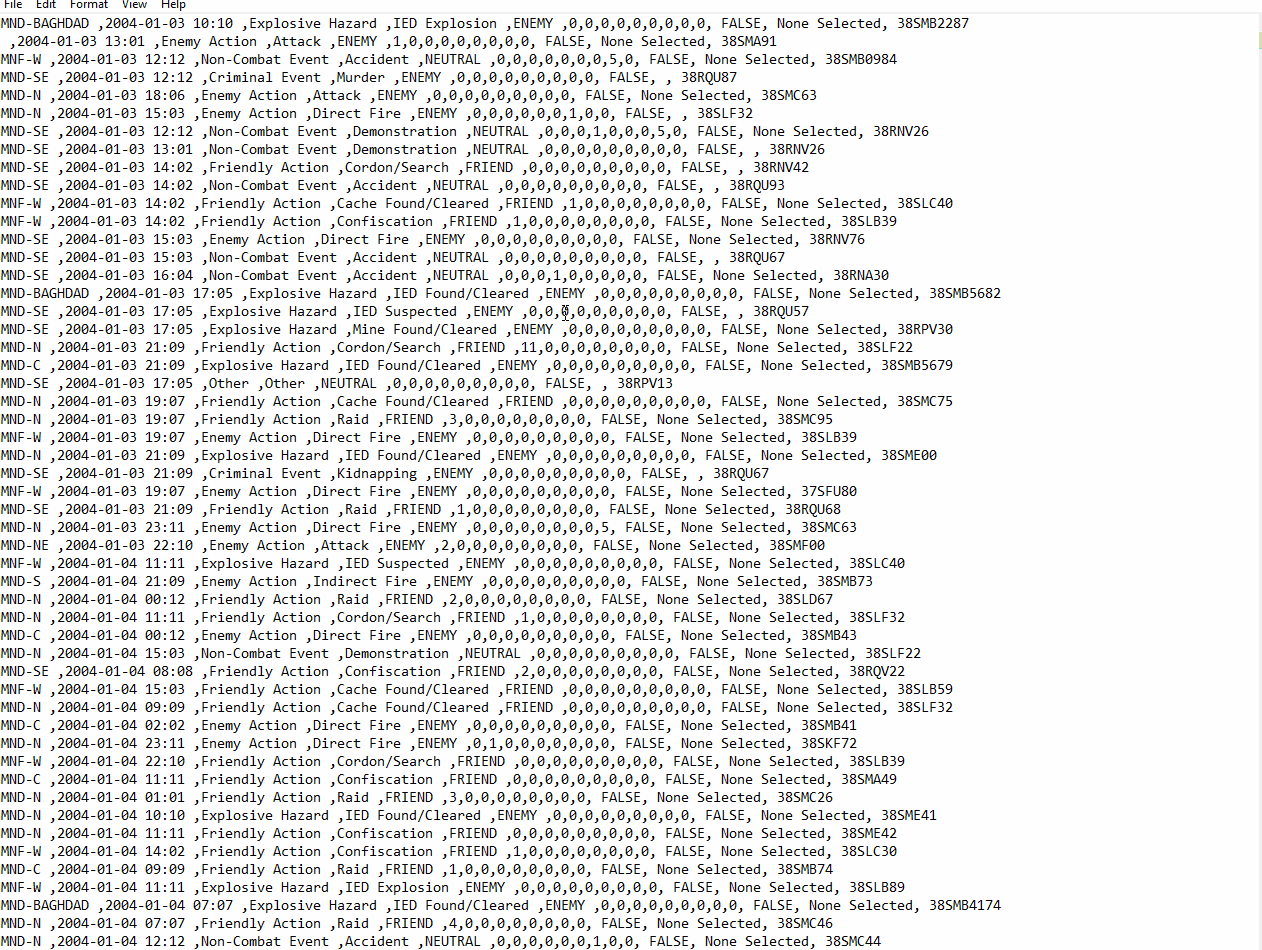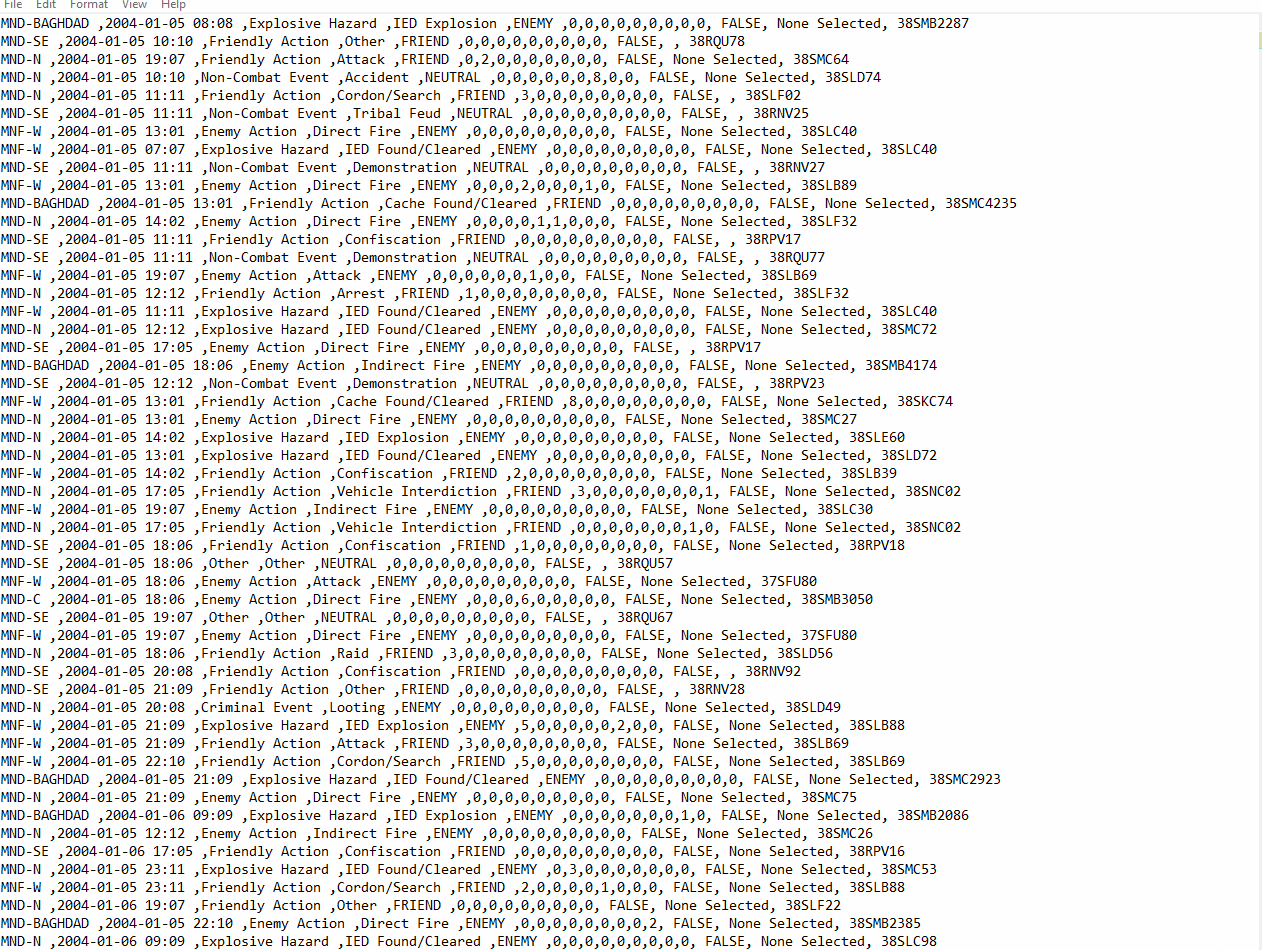
Feel free to use the dataset and remember:
“A GREAT POWER COMES WITH A GREAT RESPONSIBILITY”
About me
My name is Martin, and I am a Data Scientist.

 Except where otherwise noted, this blog's content is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Except where otherwise noted, this blog's content is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.